As many of us know Pandas is one of the most used libraries in python programming and is widely used for data analytics, data processing and machine learning data preparations. Pandas create structured tabular data objects with rows and columns.
Pandas support the following:
- Read data from multiple sources like CSV, JSON, SQL
- Supports heterogeneous collection of data
- Allows data transformations and arithmetic operations on rows and columns
As like Pandas, PySpark is used widely nowadays in the process of batch and real-time data streaming, machine learning and data analytics. PySpark is a Spark library written in python to support application and services written in Python. As PySpark support distributed data processing (multiple nodes) it can handle huge volume of data and process it 10X faster than Pandas.
In simple language advantage of PySpark over Pandas is “Pandas run operations on a single machine whereas PySpark runs on multiple machines”.
Let’s quickly cover some of the key commands in Pandas and their equivalent in PySpark:
1. Read from CSV file
Pandas (Fig. 1)

PySpark (Fig. 2)
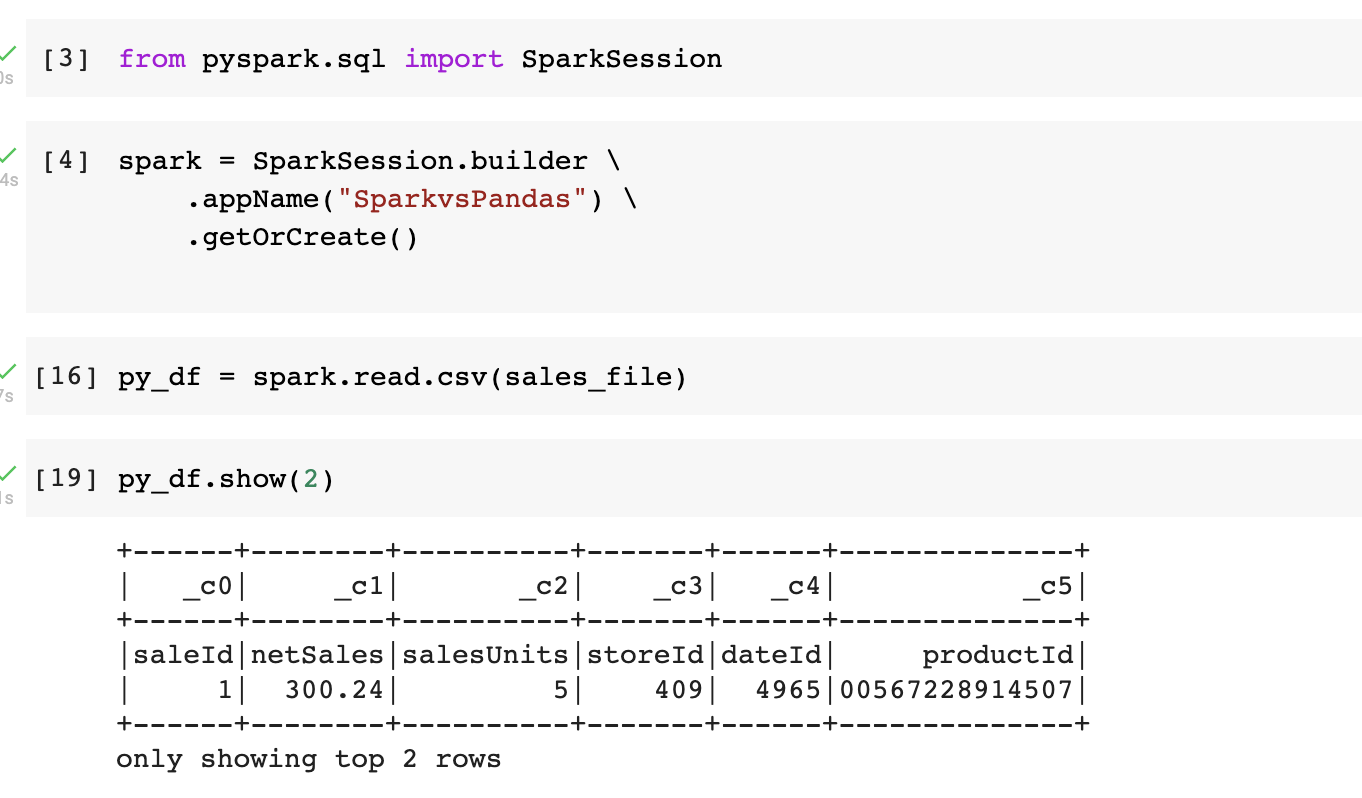
Where “sales_file” is the file path (e.g., /usr/local/dataset/sales.csv)
2. Preview Data
If you observed in the above Figs. 1 and 2, pandas use head() function and whereas pyspark uses show() function to preview the dataframe.
3. Schema and Data Type
Pandas identify data types and column headers dynamically. No need for any special commands until we want to change column names, skip headers or change the data types of the values. Whereas in the case of Pyspark, it’s good practice to define schema with a data type to avoid null values. If the wrong data type is defined then it will return null values.
Pandas (Fig 3)

Pandas uses info() function to get the schema of the dataframe. As mentioned we can see that Pandas identified data types dynamically along wit the column names in the first row.
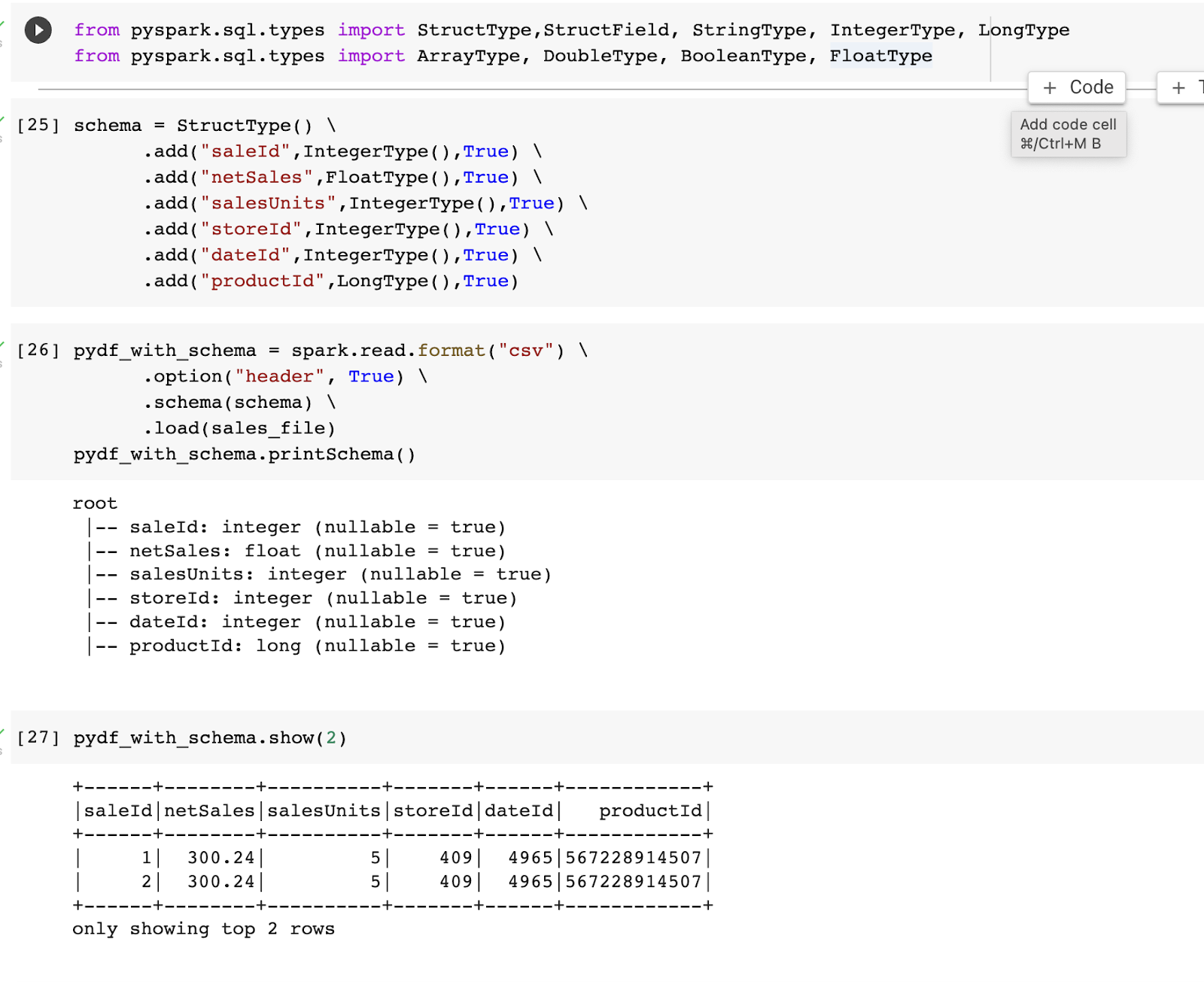
PySpark (Fig 4)

Use printSchema() function to get the schema of dataframe in PySpark. In order to define the right data type and column names we need to define schema structure as like given below:
pydf_read = spark.read.options(header=’True’, \
delimiter= =’,’).csv(sales_file)
The above command help to get the column names from the file.
To get our data clearly structured along with proper data type and column header refer to below image.
- We need to import data type.
- Define column name and data type in the same order as in dataframe in the schema.
- Call the schema inside the read() data function.
4. Get Statistics
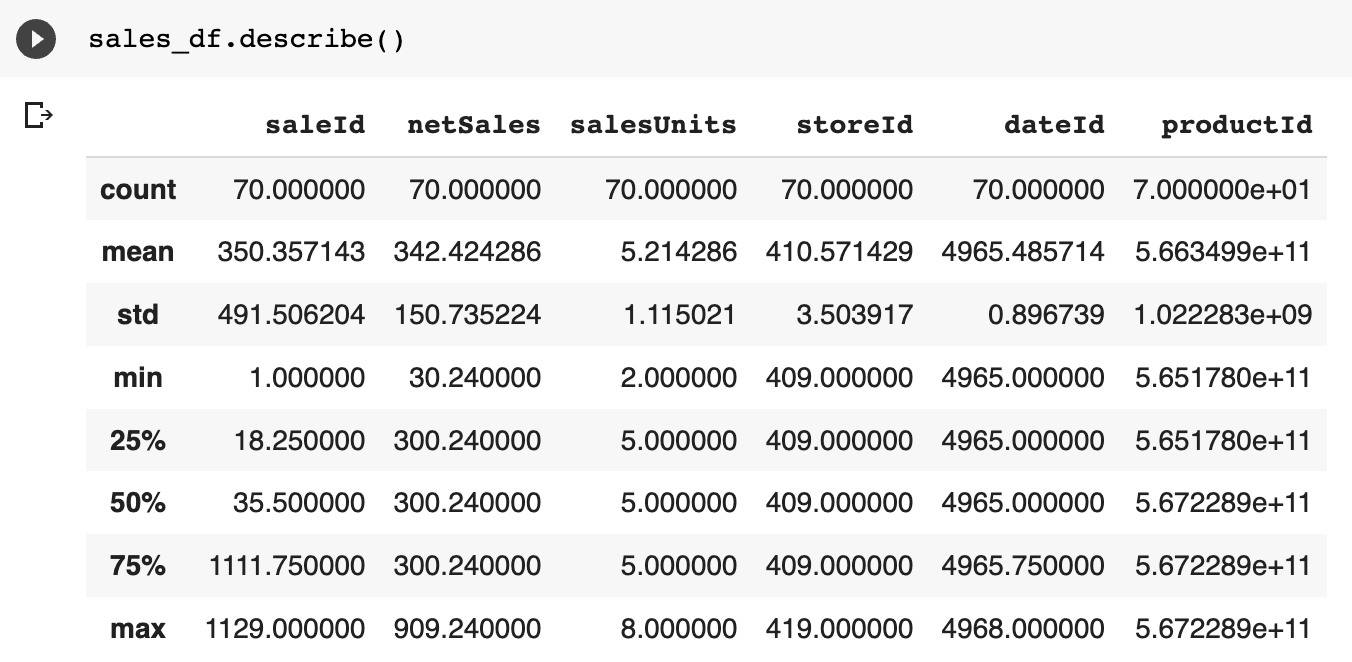
Pandas : describe()
PySpark: summary()

Thank You. You can find the code here. Follow up in the next blog to know more detail.
https://colab.research.google.com/drive/1dCJbFveSiTvv9gUFmC2fhUKWo1uNfTuZ?usp=sharing

Leave a comment